
兔子通过两只耳朵不错准确感知捕食者的一言一行2024bat365官网入口,拔擢了不同品种凡俗散播辞寰球各地的人命遗迹;雷同东谈主也需要通过双耳千里浸式享受电影视听盛宴、判断驾驶环境和感知周围活动情景。
那应用火爆的diffusion生成模子是否不错作念到径直生成合适物理寰球轨则的空间音频呢?
此前,经典的Text2Audio的使命不错通过文本轮廓的语义生成较为准确的单通谈音频。
可是这忽略了东谈主类与生俱来的感知双通谈音频的才智。应用角度来说,通过文本限度生成多通谈音频在影视文娱、AR/VR等规模领有伏击应用。
在这个趋势的布景下,为了增强文本关于多通谈音频生成的限度,港科大败邮团队初次从数据、模子和评价圭臬角度都翻新性的将限度声源标的纳入到生成范围内。
掀开新闻客户端 提高3倍畅达度什么是空间音频生成?
什么是空间音频?
似乎能够通过声息判断事物标的和情景是天然东谈主与生俱来的才智。生物声学 (Bioacoustics)是早在20世纪便进行了深化的探索。东谈主能感知声息的场地,主要来自以下三个方面:
ITD (主要不同):Interaural Time Difference-耳间时刻差。即由于双耳耳间距离导致声息到达两只耳朵的时刻不一样。这一丝是双通谈的主要各异。
ILD:Interaural Level Difference-耳间声强差。即由于双耳耳间距离导致声息到达两只耳朵的强度和衰减不一样。这一丝是缓助形式,在实质生成中发现这点较难度量,基本能量一致。
耳蜗、耳谈和头骨等生理结构:由于东谈主的感知系统相称复杂,况且波及物理及生理究诘,是一门相称深的知识。在Bioacoustic规模,好多东谈主用深度学习按序构建合理的的HRTF (Head-related transfer function),才能够很好的模拟生理结构。可是鉴于本文为先期探索使命,文中不探求这点的影响。

终了空间音频生成有关的时间门道?
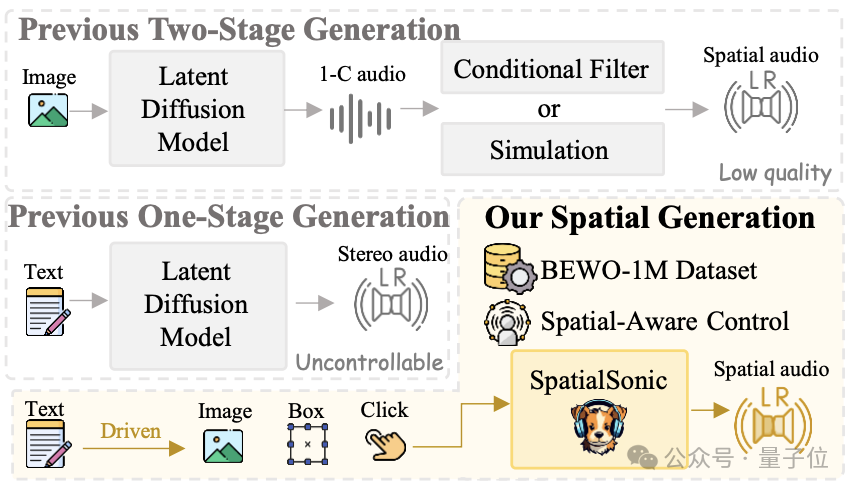
1、双阶段决策:率先通过平常text2audio的模子生成单通谈音频,然后通过仿真或者可学习的滤波器进行串联。使得最终能够得回多通谈的空间音频。这种系统彰着不够鲁棒况且无法顺应复杂场景的生成任务。
2、此前的单阶段决策:天然这类系统能够生成stereo音频,可是远远不具备生成spatial音频的限度才智。
3、该究诘决策:建议了从数据集、按序和评估运筹帷幄的一条龙惩办决策,较好的提高了关于spatial音频的限度。
数据构造:让机器“耳听八方”的数据工场
在本项究诘中,数据构造是整个系统的基石!
想要生成各个方朝上的音频,就必须让生成模子意会方朝上的折柳。比如想要让系统生成摩托自左向右行进,就需要提供摩托在左、在右、自左向右和自右向左的音频让系统显然折柳。这么音频相聚的资本彰着口舌常无边的,为什么不作念一个高效的“数据工场”呢?
接下来,带人人揭秘BEWO-1M(Both Ears Wide Open 1M)数据集的“坐蓐活水线”。
为什么需要BEWO-1M?
现如今一般的音频-翰墨数据集都缺少明确的空间信息花样,比如即便有双通谈音频,配套的翰墨花样也只是“汽车驶过”,而莫得具体场地信息(比如“汽车从右前哨驶向左前哨”)。这关于生成具有标的感的空间音频统统不够用!
是以,需要一个超大限制的、带有丰富空间花样的双通谈音频数据集,而 BEWO-1M 应时而生。它包含卓越100万条音频-文本对,况且撑捏动态声源、多声源等复杂场景。
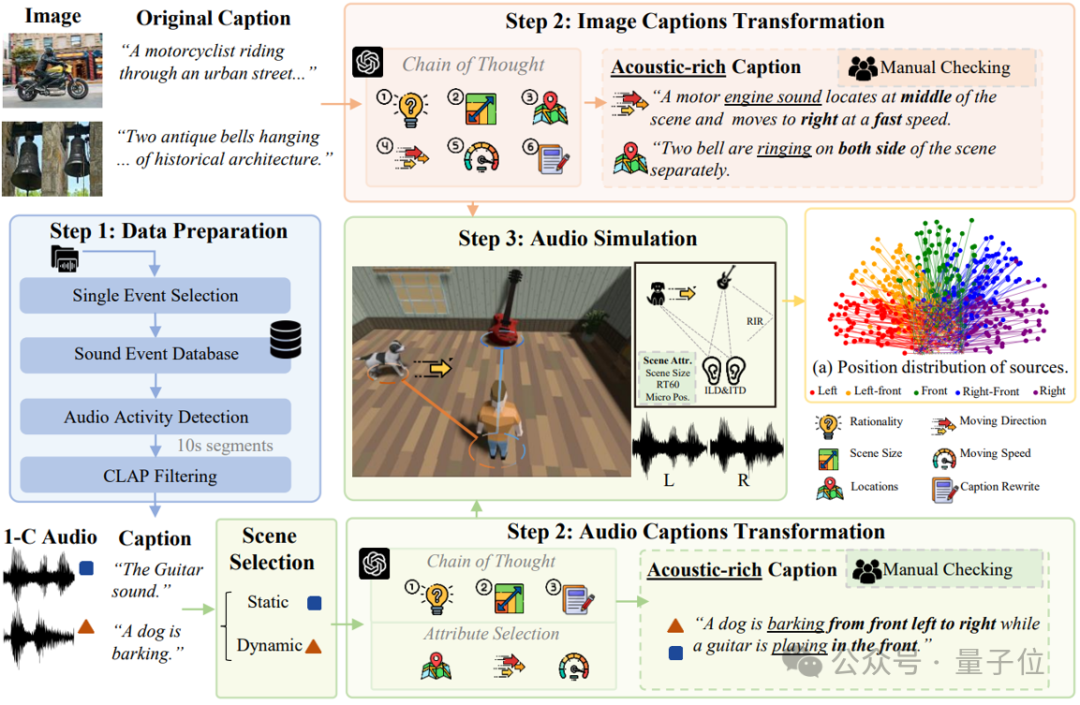
借助近些年的热点的GPT-4和严谨的仿真试验,最终通过想维链(Chain of Thought)构造了一个包含100万条、规画约2800小时音频的大限制数据集,其中包括:
单声源静态音频子集(Single Stationary):比如“猫在左边叫”。
单声源动态音频子集(Single Dynamic):比如“直升机从左飞到右”。
多声源音频子集(Double, Mixed):比如“左侧有雷声,右侧有狗叫”。
竟然寰球音频子集(Real World):还手动标注了少部分竟然录制的双通谈音频,确保测试集的竟然性。
数据各种性一览:

BEWO-1M是当今首个包含标的花样的大限制双通谈音频数据集,它不仅适用于空间音频生成,还不错膨胀到空间音频字幕生成(Appendix.G.5)、音频-文本检索(Appendix.G.6)等其他任务。在试验中,发现它能够显赫提高生成模子的空间限度才智,让机器信得过作念到“耳听八方”。
生成按序简述
感谢Stability AI的究诘者们,他们成立了用于生成双通谈的模子。可是这里生成模子存在比较彰着的音频生成问题。比如:在Stable Audio中输入prompt “A piano sound exists on the left side”, 最毕生成的钢琴声息的标的是不可控的。这是由于他们的双通谈音频统统由竟然数据测验得到,方朝上并不具有满盈的各种性。是以可控标的的音频生成模子旷日历久。
有了BEWO-1M径直finetune行不成?行!径直使用带有场地天然言语的prompt,径直进行finetune就能够让模子获取最基本的生成指定标的音频的才智。对此作家提供了一个通过天然言语限度的Gradio Demo.
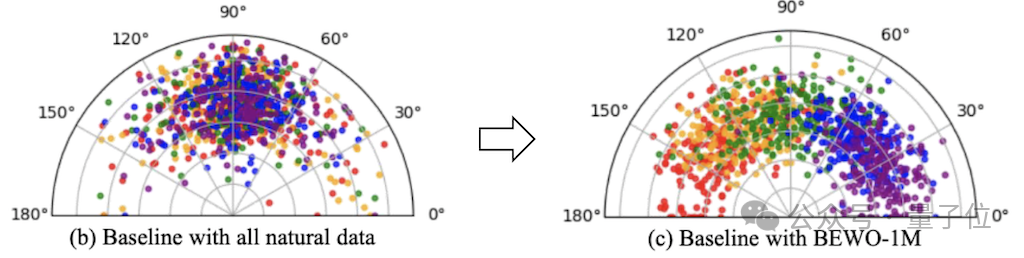
可是波及到标的天然言语意会的时候存在相称各种化的抒发。这些各种化的抒发对文本的encoder带来了极大的挑战。关于T5这个相称经典的编码模子来说,更长的文本长度会带来更长的编码和更大的意会难度。
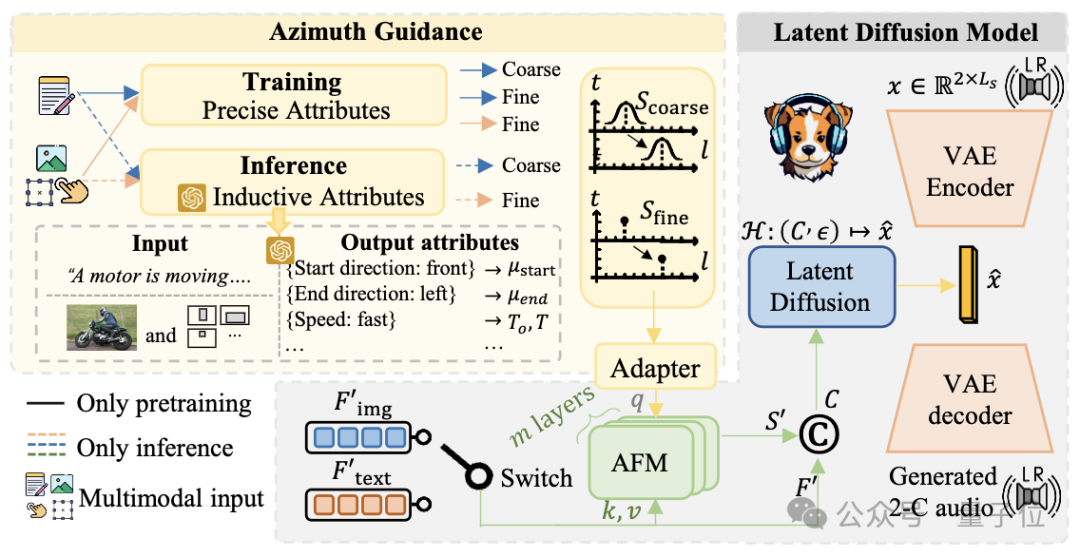
那更进一时局,为了应酬这么的挑战有两个相称天然的目的。(1)将空间限度和文本限度解耦;(2)阁下大模子关于文本的意会才智。
将空间限度和文本限度解耦.就意味着增多空间限度的斥地!空间限度的终了主要来自仿真的测验数据,作家有极为准确的仿真建模,是以在测验时的角度是精确到极少点后4位的。那么在测验的时候使用这个角度口舌常天然的。对此作家提供了一个通过精确场地信息限度的Gradio Demo.
阁下大模子关于文本的意会才智不错在推理的时候用推理和高下文体习获取可靠的标的信息(详见论文),这个标的在东谈主工考据中正确率高达90%。
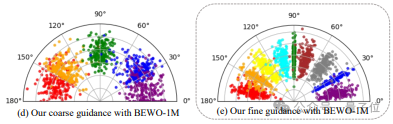
通过对空间限度和文本解耦终明晰如上图可视化的更精确的音频标的的限度。其限度性能比拟径直finetune有了精确性的提高。
试验经过中,作家发现要是使用极为准确的角度建模形式不错生成标的较为准确的音频,可是生成的音频语义各种化欠佳。是以同期成立了coarse建模形式不错得回更各种化的音频生成,可是会出现标的限度不准确的情况。
“各种性 or 限度” 这个生成千古繁难依然在这里是个trade off。
有了基于大批文本音频对的数据得到的文本限度的模子?那么奈何迁徙到其他模态上呢。而且文本编码用的是T5编码。
人所共知,T5手脚encoder+decoder的model在大模子的现今仍是淘汰了。究诘团队浅薄借助前东谈主的VL-T5接着作念了浅薄的对都终明晰浅薄的image到spatial audio的生成,这只是是给社区提供一个浅薄约略的图像斥地的音频生成的baseline。
评价和成果
为了和其他模子比较,究诘团队成立了多种语义和声源方朝上的评估算法。
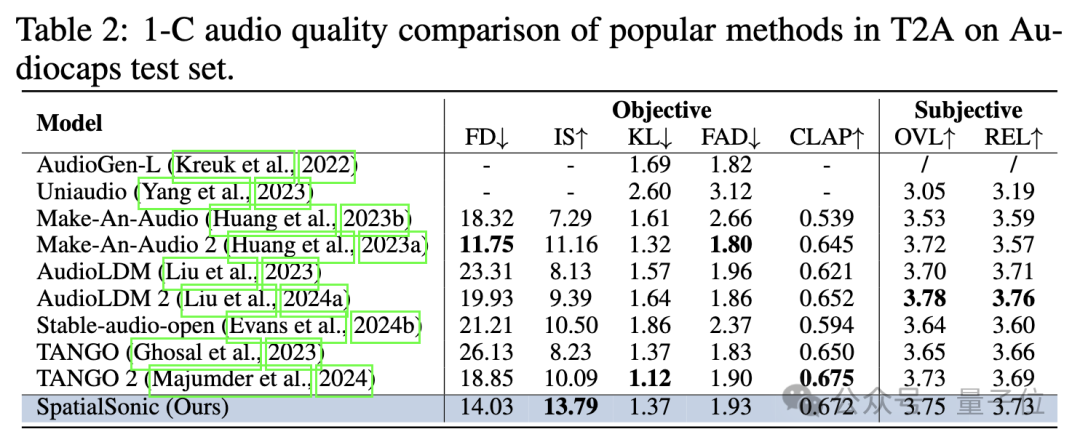
语义层面,此前Text2Audio的生成的评估算法依然灵验。作家径直声谈平均后评测语义层面上的相似进度。下表展示了以单通谈模子的评估圭臬评估SpatialSonic模子依然具有一定的先进性。
声源标的层面,究诘团队翻新性地初次建议通过ITD求出场地罪过。凭据布景所述,东谈主主要通过ITD来判断物体的大要场地,雷同也取舍ITD手脚评估按序。
此前ITD的评估一般由2种按序而来:
传统信号按序:代表为GCC-Phat
深度学习按序:代表为StereoCRW
本文阁下这两种ITD评估按序,成立了对两段音频的ITD进行不同进度的评估算法(GCC MSE、CRW MSE和FSAD)。通过这些运筹帷幄很好地展示了模子在文本斥地的空间音频生成上的优胜性。
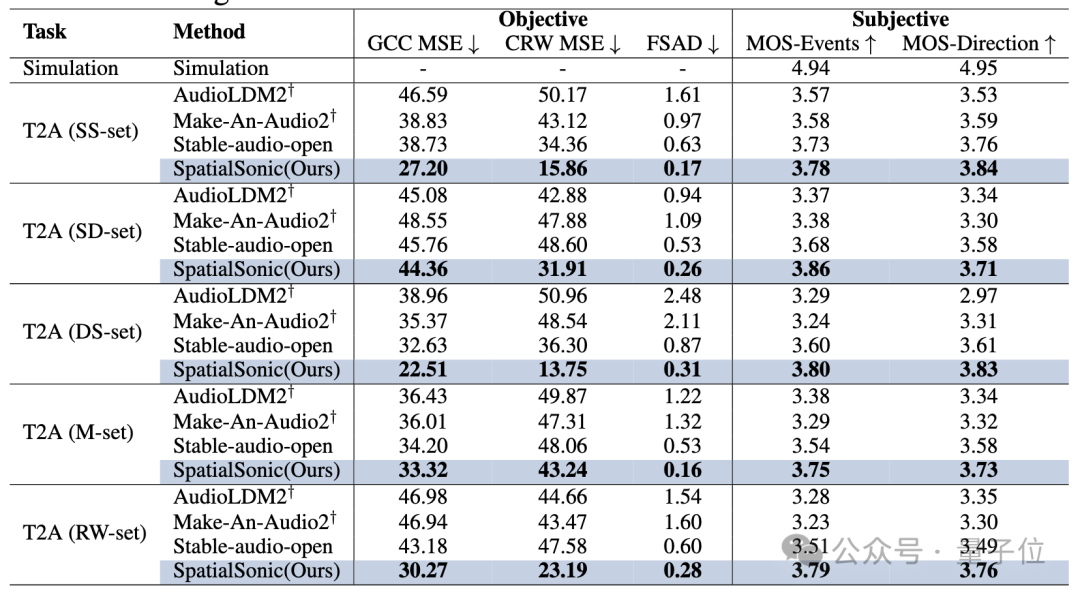
由于音频本人具有的耦合性,究诘团队深信这并不是生成音频ITD相似度的评估算法的最终形态。团队会箝制在GitHub上更新更优质的算法。更多的试验成果请参考论文。
要是你意思意思如下几个问题,请向论文中寻求谜底!
1、标的的参与进度是否会影响音频的生成质料?(Appendix.G.9)
是的。作家发现加入标的距离中间偏差越大,生成音频质料会缓缓着落。比如,质料上,纯左
2、由于标的的加入,势必导致caption长度的增多,这是否会影响音频的生成质料?(Appendix.G.10)
是的。作家发现caption长度越长,生成质料会着落。
3、不同类别的限度标的才智是否疏导?是否存在一些类别声息限度标的才智较强,一些较弱的Bias?(Appendix.G.11)
如实不同。作家发现关于个别类限度才智较强,其他类限度才智稍弱。忖度这与数据散播和GPT induction都存在关系。
曩昔瞻望
曩昔在以下多方面存在篡改空间:
引入HRTF模拟耳谈等竟然感知。
现时Visual由于使用Coco数据集存在较强的in domain问题。OOD(Out of Distribution)或者OV (Open Vocabulary)会有相称大的进取空间。
Interactive的终了依赖于SAM的性能,终了依然不口舌常优雅且存在造作蕴蓄。
VL-T5早已过时期间,大概手脚初步探索满盈,可是曩昔势必会有更优雅的形式。
— 完 —2024bat365官网入口
